Fix an “Unapproved Caller” SecurityAgent Message in Mac OS X
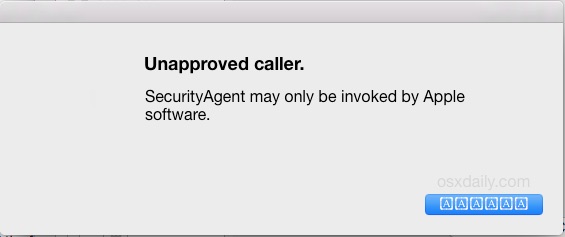
Rarely, Mac users may encounter a random error message which appears somewhat disconcerting, with an OS X pop-up message saying “Unapproved caller. SecurityAgent may only be invoked by Apple software.”
This message can appear at random when using certain apps, or after logging in or a reboot, and is sometimes followed by crashing and other bad behavior. Because the message is vague and mentions SecurityAgent and an ‘unapproved caller’ many users perceive this to be some sort of eavesdropping or attack event, but the good news is that is not the case, and you can fix the error message quite quickly and you will likely never see it again.
Fixing the “Unapproved Caller” SecurityAgent Error in OS X
The simplest way to get rid of this error message is to boot into Safe Mode, then reboot as normal. Amongst other things, this flushes out many system level caches, which will resolve the Unapproved Caller message.
- Reboot the Mac and immediately hold down the SHIFT key, continue holding shift until the loading bar appears
- Let the Mac boot into Safe Mode, which will automatically dump caches
- When completed, go to the Apple menu and choose “Restart” to reboot the Mac as normal
Let the Mac boot as normal, and you should never see the Unapproved Caller message appear again.
Why does this message appear in the first place? That’s less clear, but it appears to show up most commonly from Macs that have been upgraded from prior releases of OS X and have older third party software laying around that has to go through GateKeeper, or after installing a new app that has modified permissions, or when a user elevates access in some way. Fortunately, a safe boot is very easy to perform. And no, even though the message sounds somewhat similar, this has nothing to do with blocking callers from reaching you.
Another option is to manually trash the contents of /var/folders/ subfolders, but that is best reserved for advanced users who have made a backup of their Mac. Never modify or delete system files unless you have a backup and know what you’re doing.
Did this work for you to fix the Unapproved Caller error? Let us know in the comments if so, or what you did to resolve it.

Thank you so much! Fixed!
Fixed!
System would not boot regularly, in safe mode or from repair partition. Ran disc utility from external hard drive – no trouble found. Reinstalled OS and got this message. tried all suggestions – not only did they not work but not there is another problem – system now boots to an Apple screen with a blank white rectangle under the Apple. Not an entry field for a password, just a blank white rectangle and the cursor has disappeared. Any additional suggestions would be appreciate.
I had a problem where whenever I turned it on, the screen would just appear black and that would be the only thing appearing. I tried the shift key thing, didn’t work but then I tried the option key thing that the Julien James Davis guy suggested and it worked!! Thank you so so much!!
Booting in safe mode didn’t fix this issue, but repairing the boot volume and hard disk from the recovery partition did.
Antonio v, how did you repair the boot volume and hard disc? Rebooting in safe mode is not helping me. I must have tired it a dozen times in the past few days.
Problem has solved.
Thanks so much.. :)
The problem was solved.
Thank you so much :)
Such an amazing solution. Saved my day. Thanks a lot.
Thank you so much for this post. A huge time saver.
Works well ! thanks !
I’ve just updated my Xcode to v8.0 and I got this message when I tried to run Xcode, I followed he steps and I ran Xcode on safe mode to agree on the license, and I restarted my Mac and looks like everything is working again.
Thanks
Just happened to me, pushed an update for 10.11.6 using MDM software. Didn’t force a reboot after the install (thought it would do it on it’s own!!) and I also pushed a Java update.@ Phil above is right on, I bet this is exactly what happened. SSHing in and running a shutdown -r now command or a hard power down fixed the issue, no need for single user mode in my testing. @Themoreyou know
This happened to me after I switched my caddy with ssd and put the old hd with the problematic hd flex cable. So, in my case I think its relate with hd cable. Yeah, my hd cable somewhat need to be replaced, so I replaced it then the problem solved.
Only time I see this error is when you’ve done Apple updates that require a restart and then you try to install another piece of software. Just rebooting the computer has fixed it every time for me.
This kept happening to me, I used Disk Utility and the Safe Boot and it temporarily worked. After a certain amount of time from 5 minutes to 2 days the popup will appear whilst I use Chrome. I am using a Macbook Pro 15-inch Mid 2015 Version. If anyone can help please do so.
I’ve done it three times. Still doesn’t work for me
Thanks a lot. it did work for me. I have bought my mac a few weeks ago. this error happened because I think I have reset my macbook. I was very worried when seeing the pop-up. thank you very much
Thanks a lot . It worked perfectly.
Error showed up after a disastrous and ill-advised push by campus IT (as described by yahyah). This fix worked.
I see this message on our campus when we push updates out across the network. It occurs when an update is interupted.
Does your “push” include automatically running the updates or does the workstation user do this at his leisure? If automatically running, try to automate the process before 7 a.m. when few would get the chance to interrupt it.
Also, wondering why you would need to push any Apple updates, since the preferences can be set for this to occur automatically. You won’t have disasters like you would have with Windows updates.
You guys are crazy for real cuz it works!!!! Massive respect!!!!! Thank you guys and may God bless you!!!! Have a great day!
Your directions worked like a charm. Simply reboot holding the shift button. Then restart. I am now able to e-sign my pdf’s.
Thank you!
Does that mean you were getting the pop-up message when e-signing PDFs?
yes that worked thank you very much i was frightened
Works for me. Thanks!
Worked for me. Thanks!
I’m by no means an expert so I don’t really know what would cause (a) this error message to come up in the first place or (b) why this get-around (below) happens to work, but – for me anyway – if you hold down the Option Key at Start Up (as though you were wanting to boot up from an external drive) & then choose your hard drive from the prompt, it avoids this message coming up & the computer runs fine from there.
No promises but if you’re seeing this error message, maybe give my suggestion a go. And if anybody knows the technical reason why this little cheat has circumnavigated the problem for me at least, I’d be interested to know..?
Holding down the Option Key at Start Up worked, Thanks So Much!
The problem is i cant even restart my com the message just keep appearing after i close it and keeps on appearing non stop
Greetings,
I’ve noticed this error pop up when you apply system updates via ARD. Until you restart the computer, this message will render your system useless.
~Tom
What is “ARD”? Apple updates come via the App Store on the Dock.
ARD (Apple Remote Desktop) https://itunes.apple.com/gb/app/apple-remote-desktop/id409907375?mt=12
It’s not rarely anymore. Thanks, Jonathan.
@Vasco: If it is not rarely anymore, it must be more often. This is like saying about a crack in a windshield, “It is not small anymore.”
This comment is less than useful now and more than petty.
Didn’t resolve the problem for me.
When this was happening to me (all the f****** time) nothing would work, even this safe mode boot. I saw some people say that they took their mac to apple and got the hdd cables and motherboard replaced (for an obscene amount of money) some people said they just got their hdd cables replaced. I trusted them and went with my gut and bought an hdd cable from amazon for about 30 pounds (it’s combined with the IR sensor and sleep LED, hence 30 pounds) and replaced it myself, since then i have never seen this message :)