Show the Location Path of Current Wallpaper in Mac OS X

Ever set a desktop background picture on the Mac and have no idea where the original wallpaper image is stored in OS X? Maybe you set an image from the web and lost it, or maybe you’ve wondered where that default background image is stored so you can share it with your iOS device or another Mac? Me too, and there’s a way to quickly find the original file location of what is set as the desktop wallpaper on a Mac.
By using a defaults write debug command, you can display the full path to the currently active desktop image, directly printed on the wallpaper itself.
Here’s how to show the file path to the currently active wallpaper in Mac OS X:
- Launch Terminal in /Applications/Utilities/
- Type the following defaults write command:
- Go to the desktop to see the path printed over the wallpaper images
defaults write com.apple.dock desktop-picture-show-debug-text -bool TRUE;killall Dock
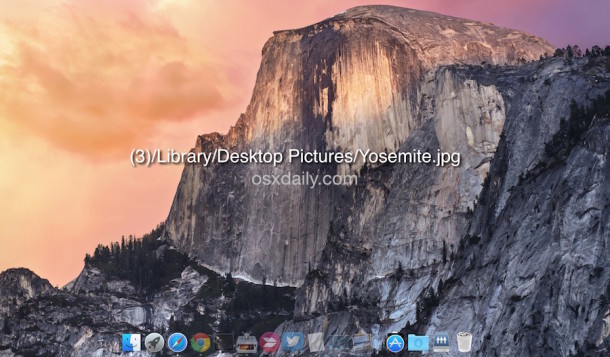
After you’ve retrieved the desktop picture (use Command+Shift+G to bring up the Go To Folder window), or done what you have needed to do, you can hide the path text by using the following command:
defaults delete com.apple.dock desktop-picture-show-debug-text;killall Dock
In OS X Yosemite (10.10.x) and newer, you can use the following syntax to hide the path again:
defaults write com.apple.dock desktop-picture-show-debug-text -bool FALSE;killall Dock
Both of these commands automatically kill/refresh the Dock as well. If you’re not fond of the command line, you can find the path information in a hidden debug mode for Desktop System Preferences too.

Still works in Monterey 12.6.3 all these years later.
Thanks so much. I couldn’t find the photo used for the current wallpaper. It was a loose photo in a folder on the desktop.
I searched and searched online and this is best answer. Too bad I didn’t find it first. I would’ve saved me almost an hour.
Wow, that’s pretty cool! :)
Paul Horowitz
Thanks for the article, very useful to me.
A bit of scripting using AppleScript will be required if you had set Desktop background to randomly cycle through your Photos collection. Note that the posixaliaspath is “hardcoded” using the stem that you will discover by the above trick to reveal the debug text, i.e.
defaults delete com.apple.dock desktop-picture-show-debug-text;killall Dock
— Usage: osascript find_wall_pic n
— n = 1..4 (desktop ID)
on run argv
if (count of argv) < 1 then
set screenId to 1
else
set screenId to item 1 of argv as integer
end if
set a to (do shell script "/usr/bin/sqlite3 ~/Library/Application\\ Support/Dock/desktoppicture.db \"SELECT data.value FROM preferences INNER JOIN data on preferences.key=16 and preferences.data_id=data.ROWID where preferences.picture_id =" & screenId & "\"") as string
set posixaliaspath to "/Users/kangfucius/Library/Caches/com.apple.preference.desktopscreeneffect.desktop/69677504/DSKPhotosRootSource/" & a
set aliaspath to (POSIX file posixaliaspath) as string
–display dialog aliaspath
set posixpath to POSIX path of aliaspath
set imgfile to POSIX file posixpath
tell application "Finder" to reveal imgfile
end run
the final solution is posted here: https://discussions.apple.com/message/33344100?ac_cid=op123456#33344100
So the location of the desktop picture is wayyyy to long to fit on the screen, and I cant seen the whole thing, therefore I cant use it to find the location of the picture. Is there any way I can fix this?
Thank you, perfect. I had a user with wallpaper saved from the net so wasn’t in any pictures folder or other directory, ran this command, found in the hidden safari folder. One very happy user. Many thanks for taking the trouble to post this helpful hint.
THANK-YOU, THANK-YOU!!!!
I use a rotating desktop background where the picture changes every 5 minutes, i love this feature, yet sometimes i want to ‘pause’ it, yet there is no way to do this, maybe this can be done in code, if i like the image it is currently on and want 2 keep it for 30 minutes i have to go back into my folder of 3000 images and hunt for it (i use it for drawing inspiration, or mood improvement)… i could pick my own desktop yet i enjoy the random surprise
I have similar question as Bumby Hemmingway. I would like the path to be shown on the bottom, but also on multiple lines. The path goes across the screen, and i cannot see the filename, which is what i really want to see.
can i get the file name only?
any help out there?
thanx
Thanks! I had one stuck that I could not figure out where in the hell the file was located. Come to discover it was actually buried in the Multiscape folder–an app I cannot use effectively in El Cap, so i trashed it.
Whew.
I would also like to know how to change the location and or size of the font so that it is not in the middle of the page. Or some way to make the information be available with a right click. Any way so that I can access the file path without it being in the middle of the photo.
LIZ–
DID YOU EVER GET AN ANSWER ABOUT WALLPAPER PIX?
JAKE
I followed these instructions and my desktop picture reverted back to the default yosemite background. Now my previous background seems lost for good. Pretty upset about this
Hello! Does anyone happen to know how to get the file path to appear not in the middle but rather at the bottom of the desktop wallpaper? I’ve got many classic paintings on shuffle as backgrounds, but I can never remember their painters or titles and I’d like to keep that info on the screen as a memory aid. Obviously having the text appear in the middle of the image ruins it aesthetically; I imagine at the bottom would be a less intrusive compromise.
Thank you in advance if anyone can help with this.
I would also love to know this.
Hi- doesn’t work under 10.10.3.
The command:
defaults delete com.apple.dock desktop-picture-show-debug-text;killall Dock
returns: “Domain (com.apple.dock) not found.”
Refresh your cache, the command to disable this for OS X 10.10.x and newer is:
defaults write com.apple.dock desktop-picture-show-debug-text -bool FALSE;killall Dock
thank you SO much! When I migrated my files from my old macbook to my new macbook air, this somehow got turned on by default and I had NO idea how to get rid of it!!
The path appears, but when you do the kill command, it doesn’t work. Even when you shut down… path is still there.
I copied and pasted the kill command he listed above and it apparently worked:
defaults delete com.apple.dock desktop-picture-show-debug-text;killall Dock
so this looks good… but i have a question… can this command be used to write something else (any text y want) in the desktop?
thanks for the help…
[…] Via | OSX Daily […]
[…] Fonte: OSXDaily […]
So you find one and you find them all, /Library/Desktop Pictures/
Could be in Documents folder or somewhere else on the hard drive, that is the whole point. If it was always in the same place, why would you need to look anywhere else?