Get the Google Cache Age of a Web Page URL
You may know that Google keeps caches of web sites and pages on a somewhat routine basis, storing them in an accessible Google repository of webcaches. These caches can be extremely useful for a wide variety of reasons, but one particularly common usage of them is if a site is slow to load or suffering from temporary downtime, you can usually still access the page or site in question by going to Google’s cached version of the page. This is because that alternate version is stored on Google servers and not on the domains web servers, making the page retrievable regardless of the origin site being up or down. Of course, the big question becomes how relevant that cache is, and that comes down to cache age, since it’s not too useful to look at old cache of a site that is too outdated to be relevant for something like a news site. That’s what we’re going to cover here, quickly finding the Google Web Cache snapshot age of any URL stored on their servers.
This trick works the same on every web browser and within any operating system. That means whether you’re on Safari, Chrome, Firefox, Mac OS X, iOS, Android, or Windows, you can use this tip. There’s also no need to bust out a terminal and start querying domains with curl to pull header details, the solution is much simple than that and is done entirely through the web using simple URL modification.
This is somewhat geeky, making it most useful for web workers, web developers, and server admins. But it’s also really useful for readers who are trying to look at a site that is otherwise down due to load or otherwise.
Finding Google Web Cache Age from Any Browser
Use the following URL format:
http://webcache.googleusercontent.com/search?q=cache:URLGOESHERE
Be sure to replace “URLGOESHERE” with the proper web address of the page or site whose cache you want to retrieve and see the time for. For example, to check the Google Webcache age of OSXDaily.com you’d use the following URL:
http://webcache.googleusercontent.com/search?q=cache:osxdaily.com
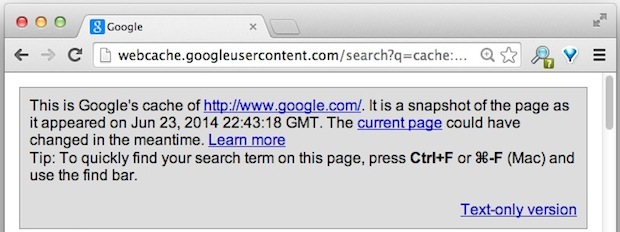
Once this loads you’ll be able to find the cache age at the very top of the URL. Most people overlook this because it’s in small print, but that’s where you’ll find the date and time of when Google’s caching service last captured the page:
This is Google's cache of http://(DOMAIN)/. It is a snapshot of the page as it appeared on Jun 24, 2014 07:03:32 GMT. The current page could have changed in the meantime. Learn more
Tip: To quickly find your search term on this page, press Ctrl+F or ⌘-F (Mac) and use the find bar. - See more at: http://webcache.googleusercontent.com/search?q=cache:DOMAIN
This type of header is shown at the top of this image in the grey box above the typical page, for those who are using this to geek out with it’s typically the first div that appears in the HTML:

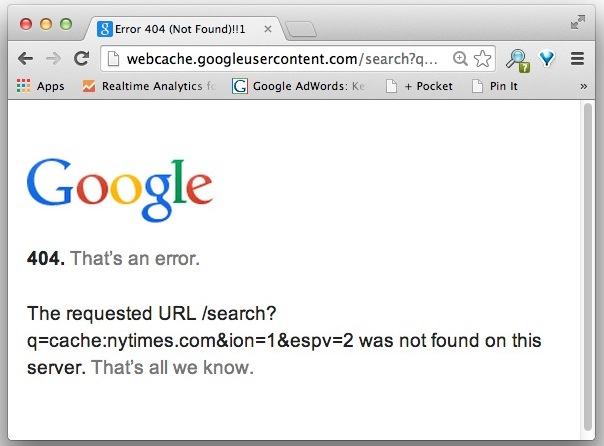
Google helpfully retains caches like this for most URL’s, but some sites either don’t allow it or just aren’t covered. For example, the New York Times and NYTimes.com does not have any cache, which will result in an error page like this:
Finding Google Cache Age from the Chrome Browser
If you’re using Google Chrome, this task is even easier, because you can simply type the following URL into the address bar to retrieve the cached version:
cache:URL-GOES-HERE
(Note it’s not cache:// but cache: without the dual slashes)
For example, from Chrome you could get the OSXDaily.com cache with this URL structure:
cache:osxdaily.com
That will pull up Google’s web cache version of the page (going to the same webcache.googleusercontent.com URL as the prior example), and this is when finding the cache age is extremely simple, just look at the top to find it, it will say something like:
"This is Google's cache of https://osxdaily.com/. It is a snapshot of the page as it appeared on Jun 24, 2014 07:03:32 GMT"
Note the date and time following the “snapshot of the page as it appeared on” portion is what you’re looking for, that’s when Googles web cache of the particular URL was captured.
So, the next time you can’t reach a particular web site but want to check it out anyway, Google’s Cache version can be a potential source, just be sure to check the age first so you know if it’s relevant or not. Happy browsing.

Bro how do i set a date to it search for?
Nice
The internet archive being suggested a lot is getting annoying. It didn’t find saved pages of my favourite artist’s blog that got removed.
It only saved one, while the rest of the blog is just useless.
I’m pretty sure every website saves data each time, I don’t get how it didn’t find all off the Website.
I search how, and all I get is that helpless website Being suggested.
Weird, I typed in our URL without the http://www. Only entered Fountainsnslate.com it said;
Your search – http://webcache.googleusercontent.com/search?q=cache:Fountainsnslate.com – did not match any documents.
Suggestions:
•Make sure all words are spelled correctly.
•Try different keywords.
•Try more general keywords.
•Try fewer keywords
I know the site is valid and spelled correctly, So what am I doing wrong?
While useful information, this article does not go deep enough.
I want to know how far back Google caches a web page and what it returns in a regular Google search.
For example, if I created a web page on January 1st and I made many changes per month to that page throughout the year with the last change made on, say, September 30th to the version before it on September 15th, how far back will Google look to present a cached page to a Google searcher?
Will it show only the September 15th version and forget about all the cached versions before the September 15th iteration? Or would a Google searcher be able to call up and visit any (and all) cached versions prior to September 15th’s rendition?
As a corollary to the question, is there any way that a website developer can PREVENT previously cached pages from showing up in a Google search? Say, for example, I inadvertently published pages that I no longer want anyone to be able to see anymore, how do I ensure that no one can see those pages, even in a cached version?
If you want specific web page caches from a specific time period, the Internet Archive may be a better solution for you, which takes visual snapshots of websites and stores them for posterity. Google Cache probably updates on some schedule that is defined by the Google cache crawler, if I had to guess I would say they update it fairly often but the easiest way to find out would be to get the cache of a test page, let them recrawl it, and see if the page cache updates as well.
Anyway, you want caches to be visible because in a situation where a site is down it can still be viewed, at least for a while, through the Google cache. Google made a great feature with this.
This is a great tool to use for reading smaller sites that go down with large traffic surges so you can still read it – less common nowadays since most web sites can scale better, but back when Digg and Slashdot used to take down sites due to volume searches, it was used frequently. Maybe with a big Reddit surge it would still work that way, but I think web cache and good web hosts have eliminated most of the downtime issues.